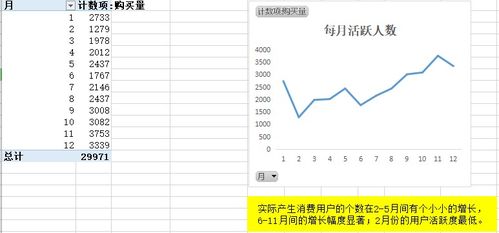
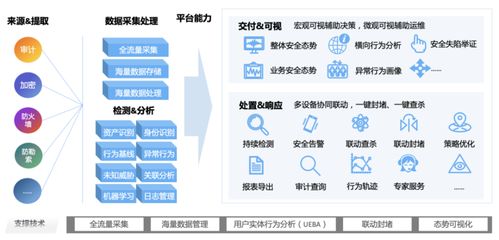
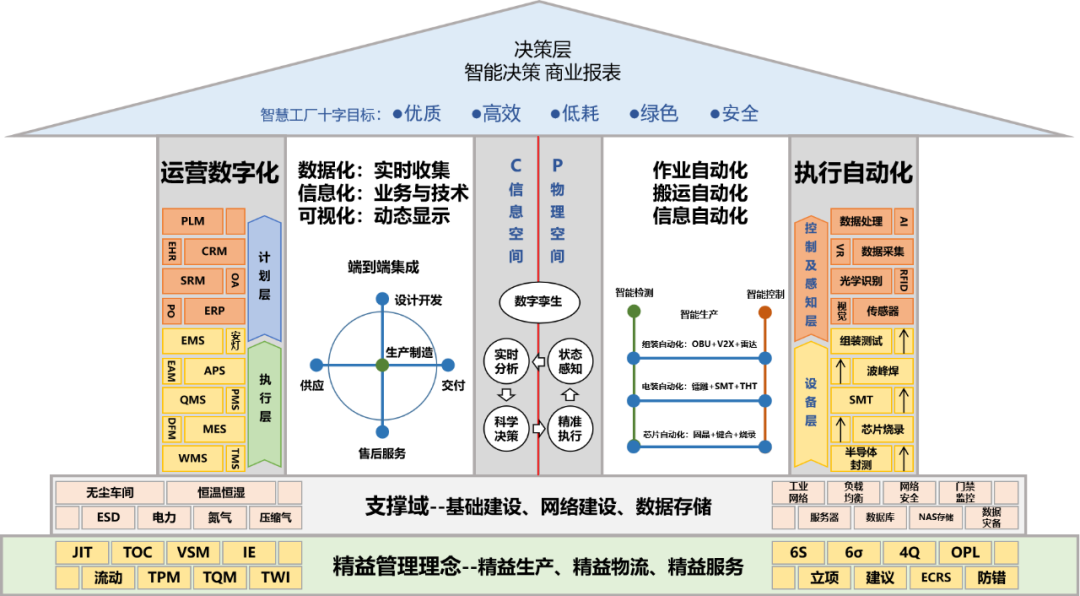
生物信息與數(shù)據(jù)處理作為現(xiàn)代生命科學(xué)研究的核心領(lǐng)域,涉及海量、多維、異構(gòu)的生物數(shù)據(jù)生成與管理。高效的存儲支持服務(wù)是這一學(xué)科得以順利開展的基礎(chǔ)保障,本課程將系統(tǒng)性地介紹其在生物信息學(xué)中的關(guān)鍵作用與實踐應(yīng)用。
一、存儲支持服務(wù)的核心作用
在生物信息學(xué)研究中,數(shù)據(jù)來源廣泛,包括基因組測序數(shù)據(jù)、蛋白質(zhì)結(jié)構(gòu)數(shù)據(jù)、臨床醫(yī)療記錄及高通量實驗數(shù)據(jù)等。這些數(shù)據(jù)往往具有體量大(如全基因組測序產(chǎn)生TB級數(shù)據(jù))、增長快、結(jié)構(gòu)復(fù)雜的特點。因此,可靠的存儲支持服務(wù)不僅需要提供充足的物理存儲空間,更要確保數(shù)據(jù)的安全性、完整性、可訪問性與長期可管理性。它是整個生物信息分析流程的基石,直接影響到下游數(shù)據(jù)處理、分析與解讀的效率和可靠性。
二、主要存儲架構(gòu)與技術(shù)
本課程將詳細(xì)講解適用于生物信息學(xué)的各類存儲解決方案:
- 集中式存儲系統(tǒng):如高性能網(wǎng)絡(luò)附加存儲(NAS)和存儲區(qū)域網(wǎng)絡(luò)(SAN),適用于需要高吞吐量和低延遲的共享數(shù)據(jù)訪問場景,例如多研究團隊協(xié)作分析同一數(shù)據(jù)集。
- 分布式存儲系統(tǒng):例如基于Hadoop的分布式文件系統(tǒng)(HDFS)或?qū)ο蟠鎯Γㄈ鏏mazon S3、OpenStack Swift),它們擅長處理海量非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù),具備良好的可擴展性和容錯性,非常適合存儲原始的測序數(shù)據(jù)、圖像文件等。
- 云存儲服務(wù):介紹公有云、私有云及混合云模型在生物信息數(shù)據(jù)存儲中的應(yīng)用。云服務(wù)提供了彈性擴展、按需付費的優(yōu)勢,并集成了豐富的計算與分析工具,極大降低了科研機構(gòu)的IT運維門檻。
- 冷/熱數(shù)據(jù)分層存儲:講解如何根據(jù)數(shù)據(jù)的訪問頻率和重要性,制定經(jīng)濟高效的存儲策略,將活躍數(shù)據(jù)存放在高性能存儲中,而將歸檔數(shù)據(jù)遷移至成本更低的存儲介質(zhì)。
三、數(shù)據(jù)管理與治理
存儲不僅僅是空間的分配,更是數(shù)據(jù)生命周期的管理。課程將涵蓋:
- 元數(shù)據(jù)管理:如何有效標(biāo)注、組織和檢索生物數(shù)據(jù),使其具有可發(fā)現(xiàn)性和可重用性。
- 數(shù)據(jù)安全與隱私:特別關(guān)注涉及人類遺傳信息等敏感數(shù)據(jù)的加密存儲、訪問控制與合規(guī)性要求(如GDPR、HIPAA)。
- 備份與容災(zāi):制定可靠的備份策略和災(zāi)難恢復(fù)計劃,防止數(shù)據(jù)丟失。
四、與計算流程的集成
存儲系統(tǒng)需要與高性能計算集群、數(shù)據(jù)分析工作流(如Nextflow、Snakemake)及數(shù)據(jù)庫(如MySQL、MongoDB)無縫集成。課程將通過實際案例,展示如何配置存儲以優(yōu)化從原始數(shù)據(jù)到最終結(jié)果的整個分析流水線的性能。
五、實踐與發(fā)展趨勢
學(xué)員將通過實驗操作,親身體驗搭建和管理一個小型生物信息學(xué)存儲環(huán)境。課程將展望存儲技術(shù)的前沿趨勢,如計算存儲一體化、基于人工智能的智能數(shù)據(jù)管理、以及為應(yīng)對超大規(guī)模生物數(shù)據(jù)(如地球生物基因組計劃)而興起的存儲技術(shù)革新。
本課程旨在使學(xué)生不僅理解生物信息學(xué)存儲支持服務(wù)的原理與架構(gòu),更能掌握其設(shè)計、選型與運維的關(guān)鍵技能,為將來從事生物信息學(xué)、精準(zhǔn)醫(yī)療或相關(guān)領(lǐng)域的研究與開發(fā)工作奠定堅實的技術(shù)基礎(chǔ)。